就是下面這一行
1 |
可以做到什麼效果呢?在某些情況下可以讓 \(O(n^2)\) 硬解 \(10^5\) 的測資。
1 | int a[100010]; |
原本要用前綴和,變爆搜就會過。
就是下面這一行
1 |
可以做到什麼效果呢?在某些情況下可以讓 \(O(n^2)\) 硬解 \(10^5\) 的測資。
1 | int a[100010]; |
原本要用前綴和,變爆搜就會過。
給定\(n, m\)下一行會有\(n\)個數字,輸出所有\(k in 1~m\),\(k\)是與所有數字皆互質的數。
1 | 3 12 |
1 | 3 |
用埃氏篩法在\(log(n)\) 的時間內做質因數分解,接著將所有數字的質因數聯集存在 bitset 中,最後判斷\(1~m\)的所有數字的質因數之中有無存於 bitset 中。
1 |
|
給定一個字串 S,輸出 AC 若 S==”Hello,World!” 否則輸出 WA。
輸⼊一行字串
1 | Hello,World! |
1 | AC |
輸出 S 中字典順序第 K 大的排列.
1 | aab 2 |
1 | aba |
1 | ydxwacbz 40320 |
輸入正整數\(N\), 輸出最大整數\(k\) 使\(2^{k} \le N\).
1 | 1000000000000000000 |
1 | 59 |
1 | 6 |
我發現,全國能力競賽的難度似乎與我預期的有落差,這一題也是我唯一一個完全解開的題目。真的好難!
「BGP 劫持(BGP Hijacking)」是⼀種透過「邊界閘道器協定(Border Gateway Protocol,BGP)」 的性質進⾏攻擊的⼿段。簡單來說,每個伺服器會宣稱⾃⼰擁有⼀段 IP,並將這個訊息傳遞給周遭的伺服器,來更新他們的路由表。周遭的伺服器也會將這個更新繼續往外傳遞,使伺服器知道要如何將封包傳遞到指定的IP。而 BGP 劫持這個攻擊⼿法,就是透過錯誤地宣稱⾃⼰擁有某⼀段 IP,或者是⾃⼰通往擁有該 IP 的伺服器路徑更短,來使得其他路由器將 IP 往他傳遞。並透過 BGP 更新路由表的特性進⾏⼤規模的流量轉移,使得使⽤者無法存取特定的服務,或者是拿到封包之後拆解其中的內容以獲得敏感資訊。
現在,全國資訊安全能⼒競賽模擬賽要進⾏⼀場 BGP 劫持的攻防⼤賽。這場⽐賽⼀共有 N ⽀隊伍參加,每⽀隊伍會維護⼀台伺服器,之後主辦⽅每次會把⼀個封包丟給⼀個伺服器,並指定他要傳向哪個伺服器。接著每台伺服器會根據他的路由表,選擇⼀個伺服器傳遞封包,而參賽者要做的就是盡可能讓不相關的封包經過⾃⼰,從而破解其中的資訊,而封包的傳遞⽅和接收⽅則要負責保護傳遞的路徑不要被攻擊。作為全國資安第⼀把交椅,翔哥也有關注全國資訊安全能⼒競賽模擬賽,但是翔哥真的太強了,這種⽐賽的勝敗他並不放在⼼上,他關⼼的是有沒有可能⼤家都享受到⽐賽的過程。雖然傳遞的路徑會根據路由表以及接收者而異,可是這對翔哥來說是 a piece of cake。他已經預測出了 M 個封包潛在被劫持的⽅式。根據封包傳遞的性質,這些路徑必定不會讓封包在數個隊伍之間循環傳遞。
現在,翔哥想知道是否存在⼀種 BGP 劫持的狀況,使得封包會經過每⽀隊伍恰好⼀次。
輸⼊的第⼀⾏包含兩個⾮負整數 N 、M ,代表全國資訊安全能⼒競賽模擬賽⼀共有 N 個隊伍參加,且 有 M 個可能的封包劫持狀況。 接下來的 M ⾏,每⾏包含兩個正整數 si、ti,代表第 si 個隊伍拿到的封包有可能被第 ti 個隊伍劫持。 保證不存在⼀種劫持路徑使得⼀個封包可以在數個隊伍之間循環傳遞。
如果存在⼀種劫持封包的⽅式,使得每個隊伍會接⼿那個封包恰好⼀次,請輸出 N 個正整數於⼀⾏,代表封包可以依序經過哪些隊伍的伺服器,否則請輸出 −1。如果有很多種封包傳遞路徑都滿⾜條件,輸出任意⼀個都可以獲得 Accepted。
正方形(左下角座標為(0,0),右上角座標為(99,99))的格網上,有一隻靈犬要尋找一個寶物,格網上除了靈犬與寶物之外,還有一些障礙物。一般情況下,只要不超出格網的邊界,靈犬的每一步最多有 8 個方向可供選擇,如圖一;但是必須注意,只有在 A 點沒有障礙物時才可以選擇方向 1 或方向 2,只有在 B 點沒有障礙物時才可以選擇方向 3 或方向 4,只有在 C 點沒有障礙物時才可以選擇方向 5 或方向 6,只有在 D 點沒有障礙物時才可以選擇方向 7 或方向 8。如果靈犬可以從出發的位置走到寶物的位置,其總共使用的步數,理論上應有一個最小值;但是靈犬也有可能無法走到寶物的位置。過程中,靈犬不可以走到障礙物的位置上。
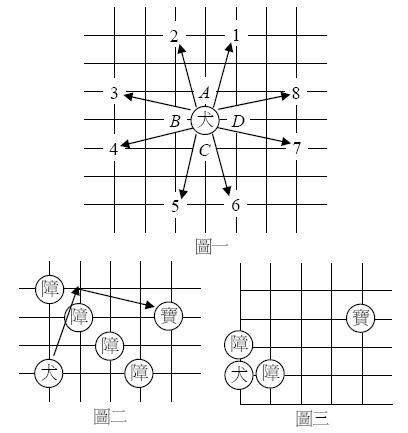
以圖二為例,有多達 4 個障礙物介於靈犬與寶物之間,但是靈犬最快只要 2 步就可以到達寶物的位置。圖三是另一個例子,靈犬的位置靠近角落,雖然只有 2 個障礙物,靈犬卻無法到達寶物的位置。
請撰寫一個程式,若靈犬可以從最初位置走到寶物的位置時,請列印出其使用之最少步數;若靈犬無法到達寶物的位置,請列印出單字 “\(impossible\)”。
第一行為一個整數 \(n\),代表障礙物的個數,\(0 \le n \le 1000\)。接下來的\(n\)行,每行表示一個障礙物的座標,其橫座標值與縱座標值間以一個空白隔開。 再下來的一行,表示靈犬的最初位置,其橫座標值與縱座標值間以一個空白隔開。 最後一行,代表寶物的位置,其橫座標值與縱座標值間以一個空白隔開。 注意:輸入之障礙物、靈犬、寶物皆在不同位置。所有橫、縱座標值均為介於 \(0\)(含)至\(99(含)\) 之間的整數。
依行走之規則,若靈犬可以從其位置走到寶物的位置時,請列印出其使用之最少步數;若靈犬無法到達寶物的位置,請列印出單字 “\(impossible\)”。
一個組合電路(combinational circuit)由線路(wires)連接一組邏輯閘(logic gates)而成,並且不包含有向迴路(directed cycle)。一個組合電路的效能決定於最後一個主要輸出(primary output)被算出來的時間。假設每一個邏輯閘所需的運算時間都是固定並且是已知的,而線路的延遲(delay)是 0。我們希望把一個組合電路所有的關鍵邏輯閘找出來。若一個邏輯閘的運算時間有任何延長,便會影響到整個電路的效能,它就被稱為關鍵邏輯閘。以圖一的組合電路為例,I1、I2、I3 是主要輸入;O1、O2 是主要輸出;圓圈代表邏輯閘,箭頭代表線路;每個邏輯閘有自己的編號以及固定的延遲時間。在圖一的例子當中,該組合電路中的 O1 會因為邏輯閘 2、4、5 的延遲,在時間 400 才會收到運算結果;而 O2 會因為邏輯閘 2、4、6 的延遲,在時間 600 才收到運算結果,因此 O2 是最後一個被算出來的主要輸出。關鍵邏輯閘分別是 2、4 以及 6 號邏輯閘,當其中一個關鍵邏輯閘的運算時間有任何延長,O2 被算出來的時間也會再往後延遲。相反地,就算 1 號邏輯閘的運算時間從 150 延長到 160,也不會影響到 O2 被算出來的時間,因此 1 號邏輯閘並不是關鍵邏輯閘。
第一行為一個整數 \(n (0 < n < 10000)\),代表一個組合電路的邏輯閘總數,每個邏輯閘的編號都不同,且範圍是介於 \(1,2,…n\) 之間的整數。第二行為一個整數 \(m (m < 50000)\),代表線路的總數。接下來的 \(n\) 行,依序列出每個邏輯閘的運算時間;每個運算時間的值是介於 0 到 600 之間(含)的整數。最後 \(m\) 行,分別列出每一條線路由某個邏輯閘的輸出接到另一個邏輯閘的輸入。 注意:為簡化輸入,我們把主要輸入(primary inputs)與邏輯閘之間的線路,以及邏輯閘與主要輸出(primary outputs)之間的線路省略。(每一個邏輯閘至少都含有一個線路輸出到另一個邏輯閘或主要輸出)
列出關鍵邏輯閘的個數。
1 | 5 4 |
1 | 1 |
1 | A |
遊戲採回合制,回合開始時若魔王位於炸彈上則所有在同一格的魔王會連同炸彈一起消失,所有未消失的魔王會先在腳下放一顆炸彈,再依據方向向量(s, t)移動。移動到邊界外的魔王視為消失。 求所有魔王消失時還有未爆彈的地點數。
n,m,r,c <= 100, k<500, |s,t|<=10
Binary Search Tree (二元搜尋樹),是用來存放多筆資料,並快速搜尋的資料結構。大概的原則就是,大的放右邊,小的放左邊。
以下為實作範例
1 |
|
以下為使用範例
1 |
|
以下我找了幾個範例
1. 在O(Nlog(26))以內找出是否有一個字母在兩個字串中均能被找到(題目連結:Two Strings | HackerRank)